Core HESML innovation
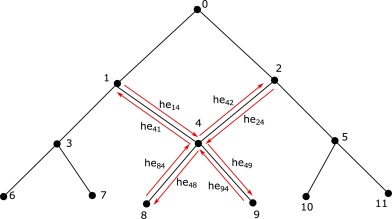
Core innovation of HESML is a linearly scalable in-memory representation for large taxonomies called PosetHERep which allows the real-time computation of any topological query without any memory overhead.
PosetHERep is a new and linearly scalable representation model for taxonomies based on our adaptation of the well-known half-edge representation in the field of computational geometry, also known as a doubly-connected edge list, in order to efficiently represent and interrogate large ontologies. For more information on PosetHERep, you can read the HESML introductory paper.
Learn more about the software architecture