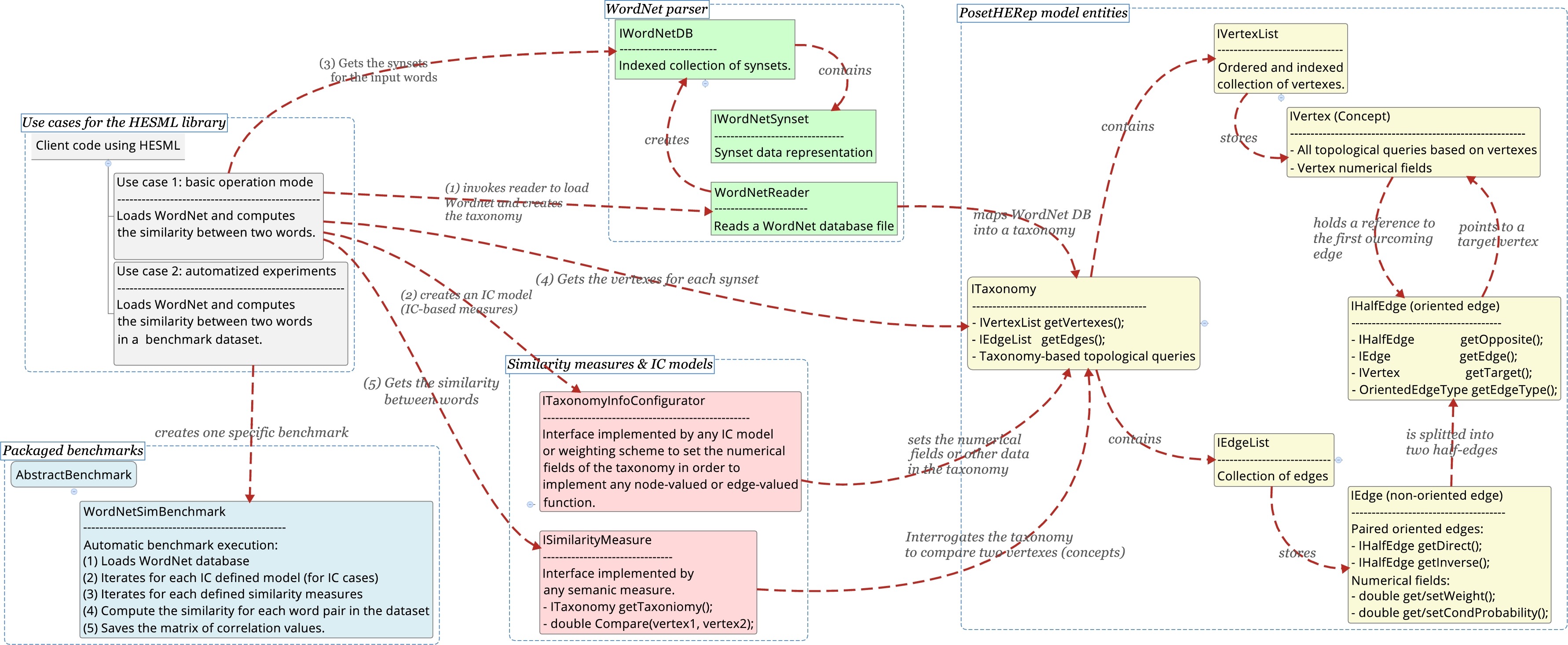
Software architecture
The HESML software library is divided into four functional blocks as follows: (1) PosetHERep model objects shown in yellow in figure above; (2) abstract interfaces implemented by the IC models or weighting schemes (ITaxonomyInfoConfigurator) and all the taxonomy-based similarity measures (ISimilarityMeasure) shown in red; (3) ontology readers shown in green; and (4) a family of automatized benchmarks shown in blue, which allow reproducible experiments on ontology-based similarity measures, IC models, word embeddings and word similarity benchmarks with different WordNet versions, SNOMED-CT, MeSH, GO and OBO-based ontologies to be easily implemented, as well as computing and saving the raw output similarity values or matrices with Pearson and Spearman correlation values. The automated benchmarks allow the efficient and exact replication of the experiments and data tables introduced in a series of papers in the area. These latter automatized benchmarks can be defined in several XML-based file formats, which allows the definition of large experimental surveys without any software coding. All HESML objects are provided as private classes which implement a set of Java interfaces, thus, they can only be instantiated by invoking the proper factory classes. All the similarity measures, IC models or weigthing schemes are invoked with a reference to the base taxonomy object (ITaxonomy) as an input argument, which provides a complete set of queries to retrieve all types of information and topological features. The children, parent, subsumed leaves, ancestor and descendant (hyponym) sets are computed on-the-fly, while the nodes and edges hold the IC values and weights respectively. Any IC model or weighting scheme is defined as an abstract taxonomy processor whose main aim is to annotate the taxonomy with the proper IC values, edge-based weights, concept probabilities or edge-based conditional probabilities. The node-based and edge-based data is subsequently retrieved by the ontology-based semantic similarity measures in their evaluation.
The PosetHERep representation model
PosetHERep is a new and linearly scalable representation model for taxonomies which is introduced herein for the first time. PosetHERep is based on our adaptation of the well-known half-edge representation in the field of computational geometry, also known as a doubly-connected edge list, in order to efficiently represent and interrogate large ontologies.
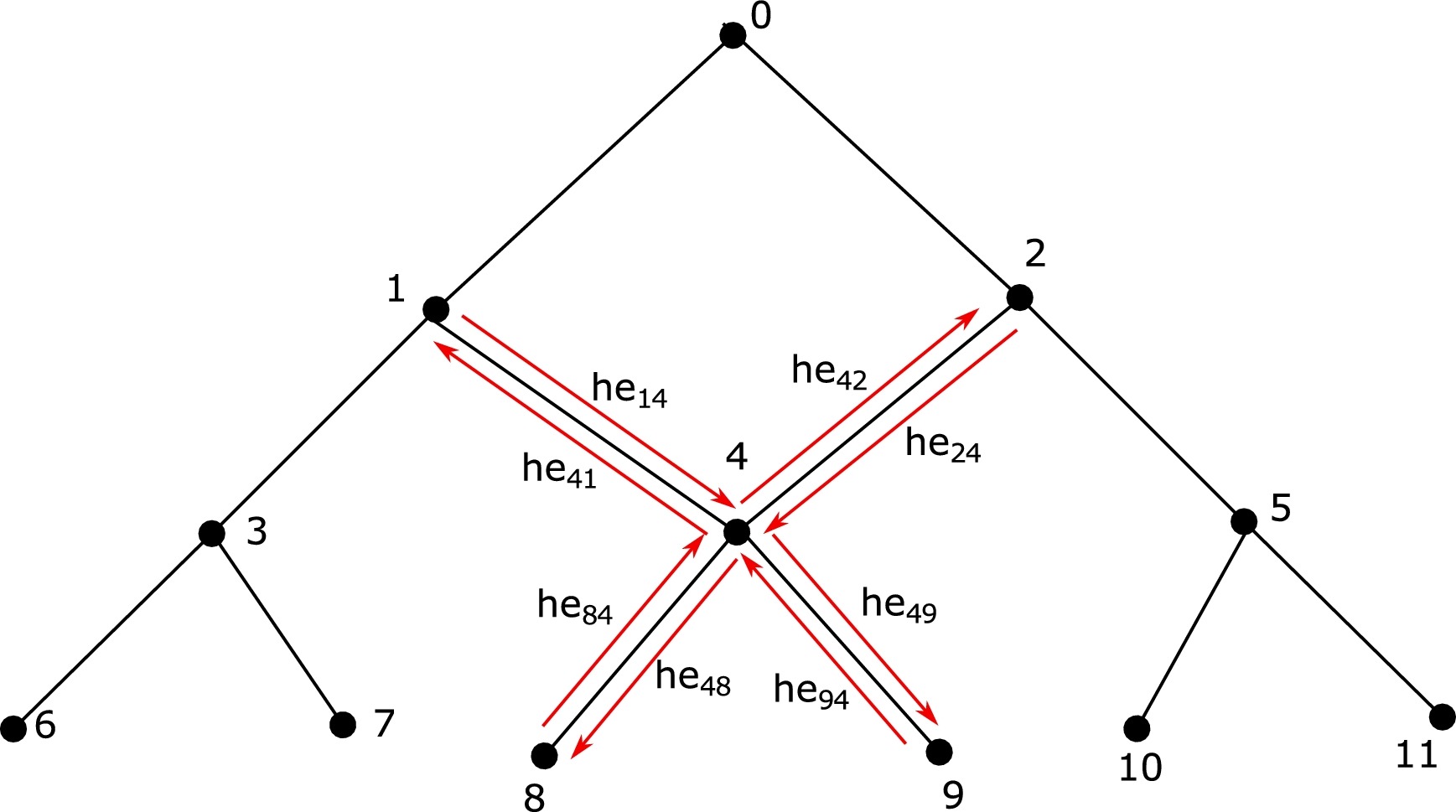
PosetHERep model is the core component of the HESML architecture, it being the main responsible for their performance and scalability. Figure below shows the core idea behind the PosetHERep representation model: all the outcoming and incoming oriented edges (half-edges) from any vertex are connected in such a way that their connection induces a cyclic ordering on the set of adjacent vertices. Given any single or multiple-root taxonomy $\mathcal{C}=\left( C,\leq_{C}\right)$ we can define its associated graph $G=\left( V,E\right) $ in the usual way, in which every concept $c_{i}\in C$ is mapped onto a vertex $ v_{i}\in C$ and every order relationship between a parent concept and their children is mapped onto an oriented edge, hereinafter called as a half-edge.
The core component of the \emph{PosetHERep} model is the neighbourhood iteration loop algorithm detailed in HESML introductory paper and three half-edge-valued functions as follows: (1) the Target function returns the vertex which the oriented edge points, (2) the Next function returns the next outcoming half-edge for each incoming half-edge to any base vertex, and (3) the Opposite function returns the opposite and paired half-edge. PosetHERep is based on the following topological consistency axiom: all the incoming and outcoming half-edges of any vertex are connected in such a way that a full cycle of the neighbourhood iteration loop returns the set of adjacent vertices for any taxonomy vertex. The HESML method that inserts the vertices into the taxonomy is mainly responsible for the verification of the latter axiom.
The PosetHERep model allows most topological queries to be answered in linear time, providing a very efficient implementation for all the graph-traversing algorithms, such as the computation of the depth of the vertices, ancestor and descendant sets, subsumed leaf sets, and the length of the shortest path between vertices, among others.